Two mathematical tidbits that I came across recently, posted mainly for my own benefit.
1. L1 distance between probability density functions
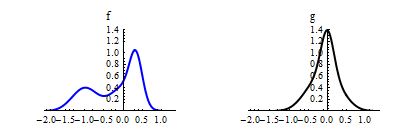
If  and
and  are two random variables with densities
are two random variables with densities  and
and  , respectively, the density
, respectively, the density  of the scaled variable
of the scaled variable  is
is
 = \frac{1}{a} f\Big(\frac{x^*}{a}\Big)\,,")
and similarly for  , where
, where  . Using this transformation rule, we see that the
. Using this transformation rule, we see that the  distance between and
distance between and  satisfies
satisfies
/p}\|f-g\|_p\,.")
Setting  , we get
, we get

This latter result also holds for  -dimensional vector random variables (for which the transformation rule is
-dimensional vector random variables (for which the transformation rule is  = {1}/{a^m} f({x^*}/{a})") ).
).


In their book on the  approach to nonparametric density estimation, Luc Devroye and László Györfi prove a much more general version of this result, which includes as a special case the fact that distance between PDFs is invariant under continuous, strictly monotonic transformations of the coordinate axes. In the one-dimensional case, this means that one can have a visual idea about the distance between two PDFs by bringing the real line into a finite interval like
approach to nonparametric density estimation, Luc Devroye and László Györfi prove a much more general version of this result, which includes as a special case the fact that distance between PDFs is invariant under continuous, strictly monotonic transformations of the coordinate axes. In the one-dimensional case, this means that one can have a visual idea about the distance between two PDFs by bringing the real line into a finite interval like ![[-1,1]](http://s.wordpress.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=000000&s=0 "[-1,1]") by a monotonic transformation.
by a monotonic transformation.
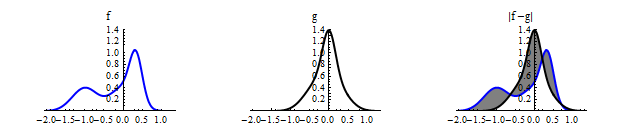
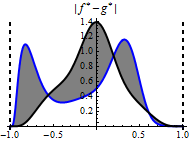
The figure below shows the transformed version of the PDFs above, via the transformations  ,
,  . The area of the gray region inside the interval below is the same as the area of the gray region in the third plot above (which is spread over the whole real line).
. The area of the gray region inside the interval below is the same as the area of the gray region in the third plot above (which is spread over the whole real line).
 You can read the proof of the general version of the theorem in the introductory chapter of the Devroye-Györfi book, which you can download here. Luc Devroye has many other freely accessible resources on his website, and he offers the following quote as an aid in understanding him.
You can read the proof of the general version of the theorem in the introductory chapter of the Devroye-Györfi book, which you can download here. Luc Devroye has many other freely accessible resources on his website, and he offers the following quote as an aid in understanding him.

2. L1 penalty and sparse regression: A mechanical analogy
Suppose we would like to find a linear fit of the form  to a data set
to a data set ") , where
, where  ,
,  , and
, and  . Ordinary least-squares approach to this problem consists of seeking an -dimensional vector
. Ordinary least-squares approach to this problem consists of seeking an -dimensional vector ") that minimizes
that minimizes
^2\,.")
One sometimes considers regularized versions of this approach by including a “penalty” term for  , and minimizing the alternative objective function
, and minimizing the alternative objective function
^2 + \lambda P(\mathbf{\beta})\,,")
where  is a tuning parameter, and
is a tuning parameter, and ") is a function that measures the “size” of the vector
is a function that measures the “size” of the vector  . When
. When
 = \sum_{j=1}^m |\beta_j|^2 = \|\mathbf{\beta}\|_{2}^2") ,
,
we have what is called ridge regression, and when
 = \sum_{j=1}^m |\beta_j| = \|\mathbf{\beta}\|_{1}") ,
,
we have the so-called LASSO. Clearly, in both cases, increasing the scale  of the penalty term results in solutions with “smaller” , according to the appropriate notion of size.
of the penalty term results in solutions with “smaller” , according to the appropriate notion of size.
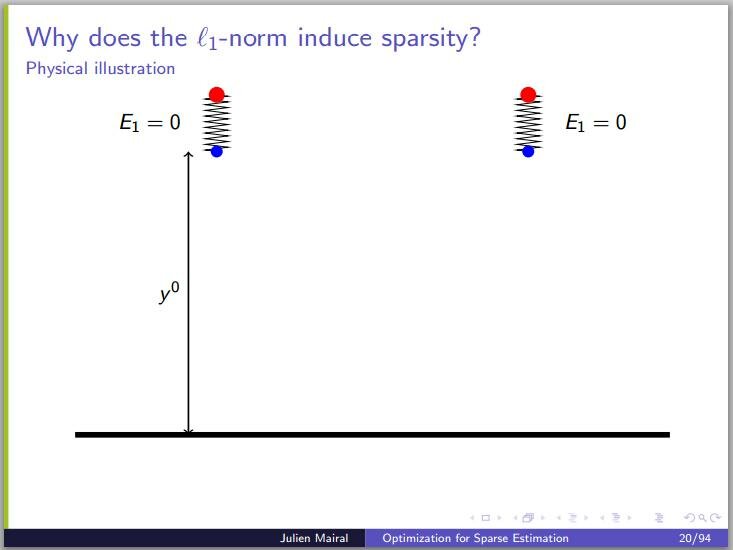
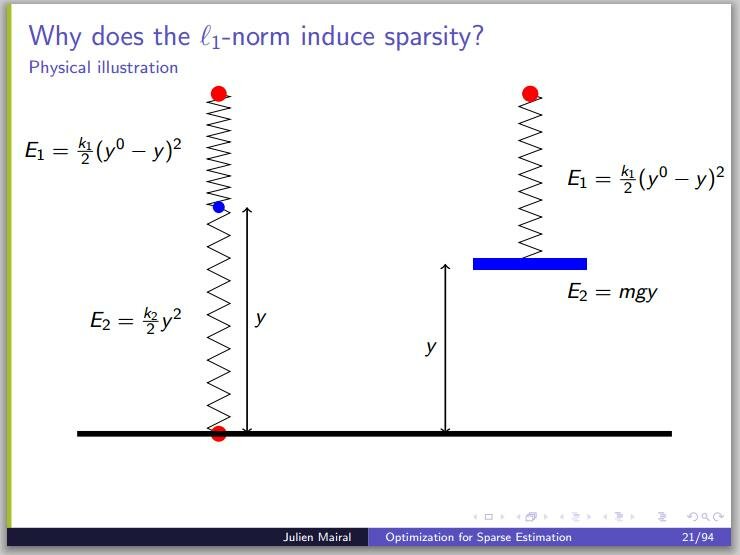
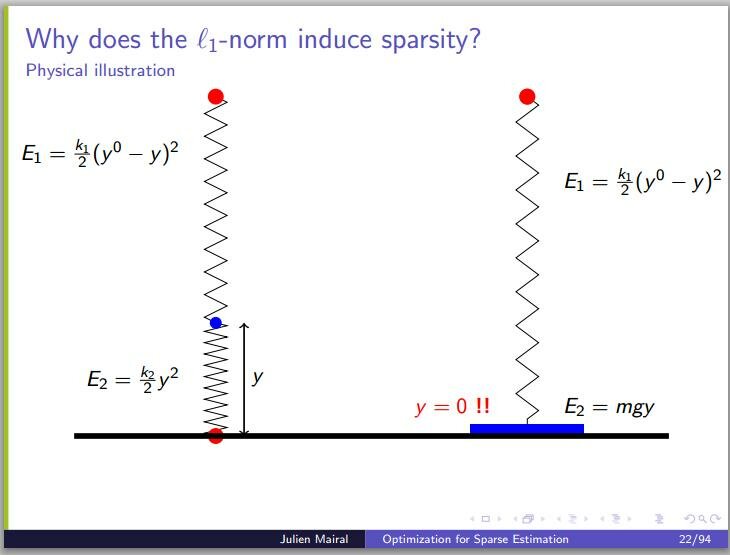
Perhaps a bit surprisingly, for the case of penalty (LASSO), one often gets solutions where some  are not just small, but exactly zero. I recently came across an intuitive explanation of this fact based on a mechanical analogy, on a blog devoted to compressed sensing and related topics. The following three slides reproduced from a presentation by Julien Mairal perhaps do not exactly constitute a “proof without words“, but are really helpful nevertheless. The
are not just small, but exactly zero. I recently came across an intuitive explanation of this fact based on a mechanical analogy, on a blog devoted to compressed sensing and related topics. The following three slides reproduced from a presentation by Julien Mairal perhaps do not exactly constitute a “proof without words“, but are really helpful nevertheless. The  terms in the figures represent the
terms in the figures represent the  and versions of the penalty function as “spring” and “gravitational” energies, respectively. Increasing the spring constant
and versions of the penalty function as “spring” and “gravitational” energies, respectively. Increasing the spring constant  makes
makes  smaller, but not zero. Increasing the gravity (or the mass), on the other hand, eventually makes zero.
smaller, but not zero. Increasing the gravity (or the mass), on the other hand, eventually makes zero.
In case you haven’t seen it before, here is a visual from the original LASSO paper by Tibshirani, comparing and penalties in a two-dimensional problem ( denotes the solution of the ordinary least squares problem, without any constraint or penalty):
denotes the solution of the ordinary least squares problem, without any constraint or penalty):
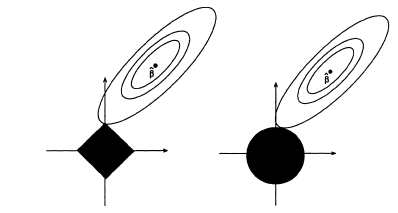
This provides another intuitive explanation of the sparsity of solutions obtained from LASSO. In order to make sense of this figure, you should keep in mind that the regularized problems above are equivalent to the constrained problem
^2\,,\\ \\\text{subject to } P(\mathbf{\beta})\le t\,,")
where  is analogous to the tuning parameter , and stands for or penalty, as above. (If this was a bit too cryptic, you can take look at the original LASSO paper, which, according to Google Scholar, has been cited more than 9000 times.)
is analogous to the tuning parameter , and stands for or penalty, as above. (If this was a bit too cryptic, you can take look at the original LASSO paper, which, according to Google Scholar, has been cited more than 9000 times.)
Like this:
Like Loading...
